什么是 Triton
Triton 可以通过相对较少的努力达到峰值硬件性能,例如,Triton 可用于在 25 行代码内编写与 cuBLAS 性能相匹配的 FP16 矩阵乘 Kernel(这是许多 GPU 程序员都无法做到的)。
Triton 是一种 DSL 语言,是一种比较抽象的编程语言和该语言相应的编译器。Triton 将其 DSL 语法表达体系称为 triton.language,是一种依托于 Python 环境的 DSL。triton.language 是 Triton 官方提供的一套完备且高效的语法表达与编程接口体系,允许开发者在 Triton 框架内(以 triton.jit 为装饰器的 Python 函数内)更灵活,更游刃有余地编写和优化自定义的算子(operators)或处理复杂的数据流程。这些表达广泛涵盖了编写高性能算子所需的各类常规操作,包括但不限于数据加载、存储、基本运算、程序调试等核心功能。
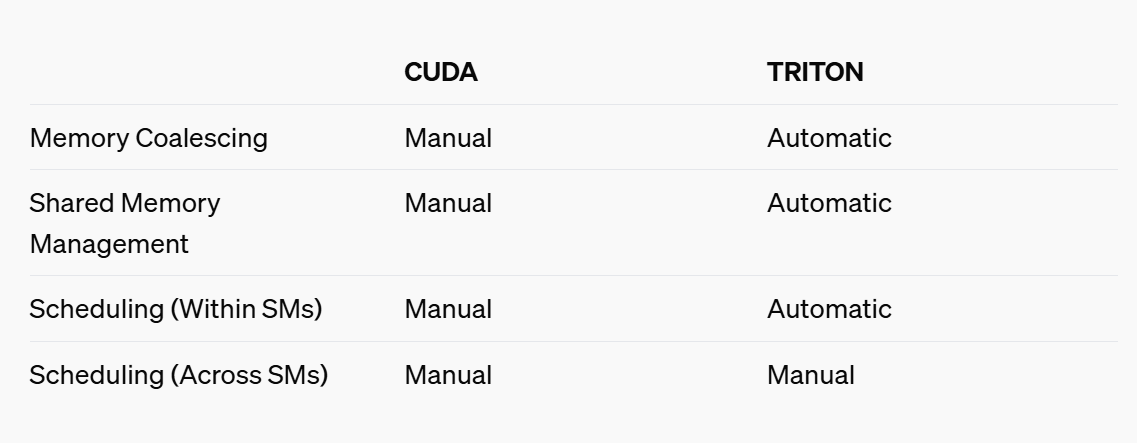
Triton 在硬件层面面向 CTA(协作线程数组) 进行优化,在软件层面则针对线程块的并行层次进行编程。Triton 相比更高级语言或者 PyTorch 框架提供的功能接口更加专注于计算操作的具体实现,允许开发者灵活地操作 Tile 级别数据读写、执行计算原语及定义线程块切分方式,特别适宜开发算子融合、参数调优等性能优化策略。相比更底层的 CUDA C /C++,甚至 PTX、SASS 等,Triton 简化了 GPU 编程的复杂性,隐藏了一些线程块以下的调度功能,改由编译器自动接管共享存储、线程并行、合并访存、张量布局等细节,降低了并行编程模型的难度,同时提高了用户的生产效率。
与 CUDA 相对而言,Triton 隐藏了线程级别的操作控制权,在编程灵活性上有所牺牲,以达到开发效率和计算能效的均衡。但 Triton 通过多层编译和多层优化,其程序性能依然可与 CUDA 媲美。
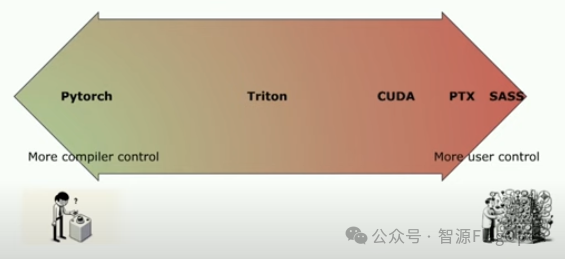
Triton 的生态融合与硬件迁移
Triton 基于 Python 语言环境,使用 PyTorch 定义的张量数据类型,Triton 函数可以顺畅地应用到 PyTorch 框架下的网络模型当中。并且,Torch Inductor 选择 Triton 作为图优化和代码生成的中间语言。
Triton 的全面开源特性也为 AI 芯片厂商的适配工作提供了便利。相较于 CUDA 封闭工具链,Triton 的代码开源和生态开放,厂商能够将体量较小的 Triton 编译器以较低成本移植到自研芯片上,并能根据自研芯片的架构特征和特有的硬件设计来灵活调整编译器的行为,从而快速添加后端并实际支持基于 Triton 的丰富软件项目。
一个 Triton 例子
听起来,OpenAI Triton 的目标是:让天下没有难写的 GPU kernel 代码?!以 vector_add kernel 为例子,看看 Triton Kernel:
import triton
import triton.language as tl
@triton.jit()
def add_kernel(x_ptr,
y_ptr,
output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)triton 通过线程块和线程索引计算每个线程应该处理的元素索引,并使用 mask 掩码来确保不会越界访问。CUDA 以线程为粒度,开发者需要手动管理线程块和线程,而 Triton 以线程块为粒度,自动处理线程调度。
使用 OpenAI Triton 进行编程,效率相对较高,但当前缺少 profile、debug 等工具,也缺失相关调优文档。
Triton 高层系统架构
Triton 的良好性能来自于以 Triton-IR 为中心的模块化系统架构,Triton-IR 是一种基于 LLVM 的中间表示,其中多维 blocks 是一等公民。
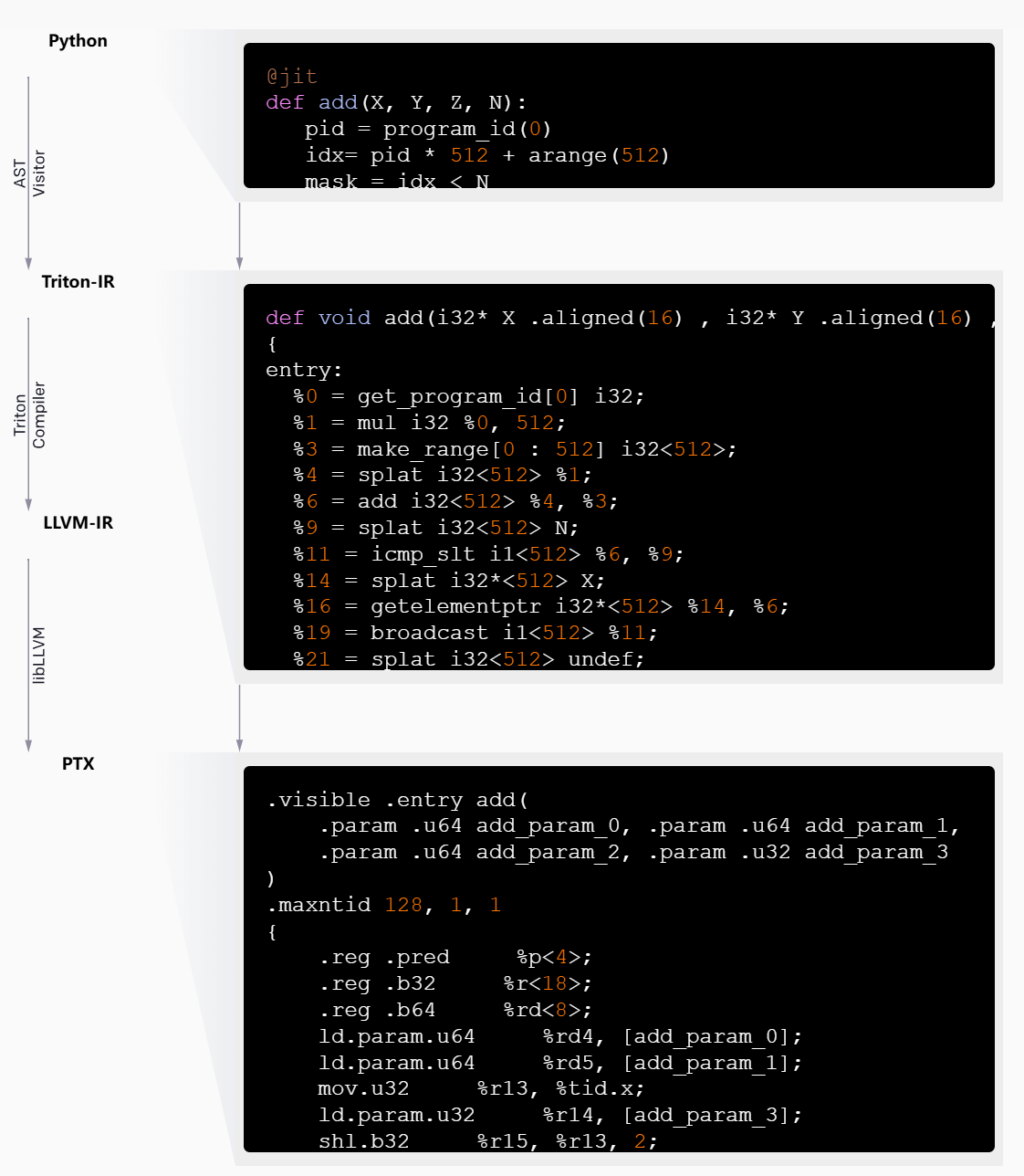
@triton.jit 装饰器通过遍历所提供的 Python 函数的抽象语法树(AST)来工作,以便使用常见的 SSA 构造算法动态生成 Triton-IR。然后,生成的 IR 代码会由编译器后端进行简化、优化和自动并行化,然后转换为高质量 LLVM-IR(最终转换为 PTX),以便在最新的 NVIDIA GPU 上执行(最新版本 Triton 在逐步支持 AMD GPUs 和 CPUs)。
参考
开启大模型时代新纪元:Triton 的演变与影响力
Triton 入门指南| Triton DSL 的特点与类型
Vector Addition — Triton documentation
Introducing Triton: Open-source GPU programming for neural networks | OpenAI
triton-lang/triton: Development repository for the Triton language and compiler
Welcome to Triton’s documentation! — Triton documentation
srush/Triton-Puzzles: Puzzles for learning Triton
Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations