问题
跨步全局内存访问对性能影响很大,且难以避免,特别是沿着多维数组的第二维度或更高维度进行数据访问时。Shared memory 可以合并全局内存访问,缓解跨步访存带来的性能下降。但 Shared memory 也会导致 bank conflict,使用时需要注意。
- 什么是跨步全局内存访问?
- 什么是 Shared Memory?
- 什么是 bank conflict?
第一个问题上一个博客中解释了,剩余两个问题在本博客中解释。
Shared Memory
Shared memory 也是 CUDA 编程中的一类内存模式,Shared memory 物理存储在片内,要比 global memory 快得多。同时,shared memory 会被分配给 thread block,该 block 中的所有 threads 均可访问。结合 thread synchronization,shared memory 有很多用途,如 user-managed data caches、high-performance cooperative parallel algorithms and to facilitate global memory coalescing.
Thread Synchronization
线程间进行数据共享时,要特别注意避免 race conditions,可能导致未知问题。因为不同线程概念上是同一时刻并发的,但分配到不同 warp 中的 thread 仍然存在先后顺序,可能碰到提前 read 某个还未 write 的数据。
为了确保在并行线程协作时获得正确的结果,必须同步线程。CUDA 提供了 __syncthreads() 语法,可以进行线程同步。__syncthreads() 后的代码,只能在该 thread block 中所有 thread 均执行完 __syncthreads() 后才可以执行。
Shared memory 常见使用场景是,先由各个线程从 global memory 中 load 数据存入 Shared memory 中(write 过程),再由各个线程从 Shared memory 中读取使用(read 过程)。在这 write 和 read 之间插入 __syncthreads() 即可保证不会发生 race conditions。
Warning
但要注意,不要在 divergent 代码中调用 __syncthreads(),会导致死锁,因为某些逻辑分支不是所有 thread 都能执行到的。尽量保证 thread block 中的所有 thread 在同一点调用 __syncthreads().
Example
#include <stdio.h>
__global__ void staticReverse(int *d, int n)
{
__shared__ int s[64];
int t = threadIdx.x;
int tr = n - t - 1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
__global__ void dynamicReverse(int *d, int n)
{
extern __shared__ int s[];
int t = threadIdx.x;
int tr = n - t - 1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
int main(void)
{
const int n = 64;
int a[n], r[n], d[n];
for (int i = 0; i < n; i++)
{
a[i] = i;
r[i] = n - i - 1;
d[i] = 0;
}
int *d_d;
cudaMalloc(&d_d, n * sizeof(int));
// run version with static shared memory
cudaMemcpy(d_d, a, n * sizeof(int), cudaMemcpyHostToDevice);
staticReverse<<<1, n>>>(d_d, n);
cudaMemcpy(d, d_d, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i])
printf("Error: d[%d]!=r[%d] (%d, %d)\n", i, i, d[i], r[i]);
// run dynamic shared memory version
cudaMemcpy(d_d, a, n * sizeof(int), cudaMemcpyHostToDevice);
dynamicReverse<<<1, n, n * sizeof(int)>>>(d_d, n);
cudaMemcpy(d, d_d, n * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < n; i++)
if (d[i] != r[i])
printf("Error: d[%d]!=r[%d] (%d, %d)\n", i, i, d[i], r[i]);
cudaFree(d_d);
}Shared memory bank conflicts
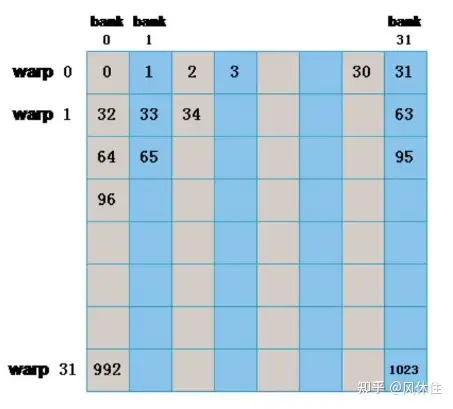
为了实现并发高访问的高内存带宽,Shared memory 被划分为大小相等的内存模块 bank,以便可以同时访问。因此,可以同时处理跨 b 个不同内存 bank 的任何 n 个地址的 load 和 store,从而产生比单个 bank 带宽高 b 倍的有效带宽。
Note
但是,如果多个线程的请求地址映射到同一个内存 bank 中不同地址时,则访问会被序列化,顺序执行。这就是 bank conflict。硬件根据需要将冲突的内存请求拆分为多个单独的无冲突请求,从而导致有效带宽下降,下降力度与冲突请求数量正相关。
有一个例外,当 warp 中多个线程寻址相同的共享内存位置时,将导致广播。在这种情况下,来自不同 bank 的多个广播将合并为从请求的共享内存位置到线程的单个广播,此时不算 bank conflicts.
GPU will raise bank conflict if different threads (int the same warp) access different addresses in a bank.
bank conflict 只发生在同一 warp 中不同 threads 访存时,不同 warp 间不会发生 bank conflict,以下两种情况不会发生 bank conflict:
- half-warp/warp 内所有线程访存不同的地址
- half-warp/warp 内所有或多个线程访存同一地址 (multicast 广播)
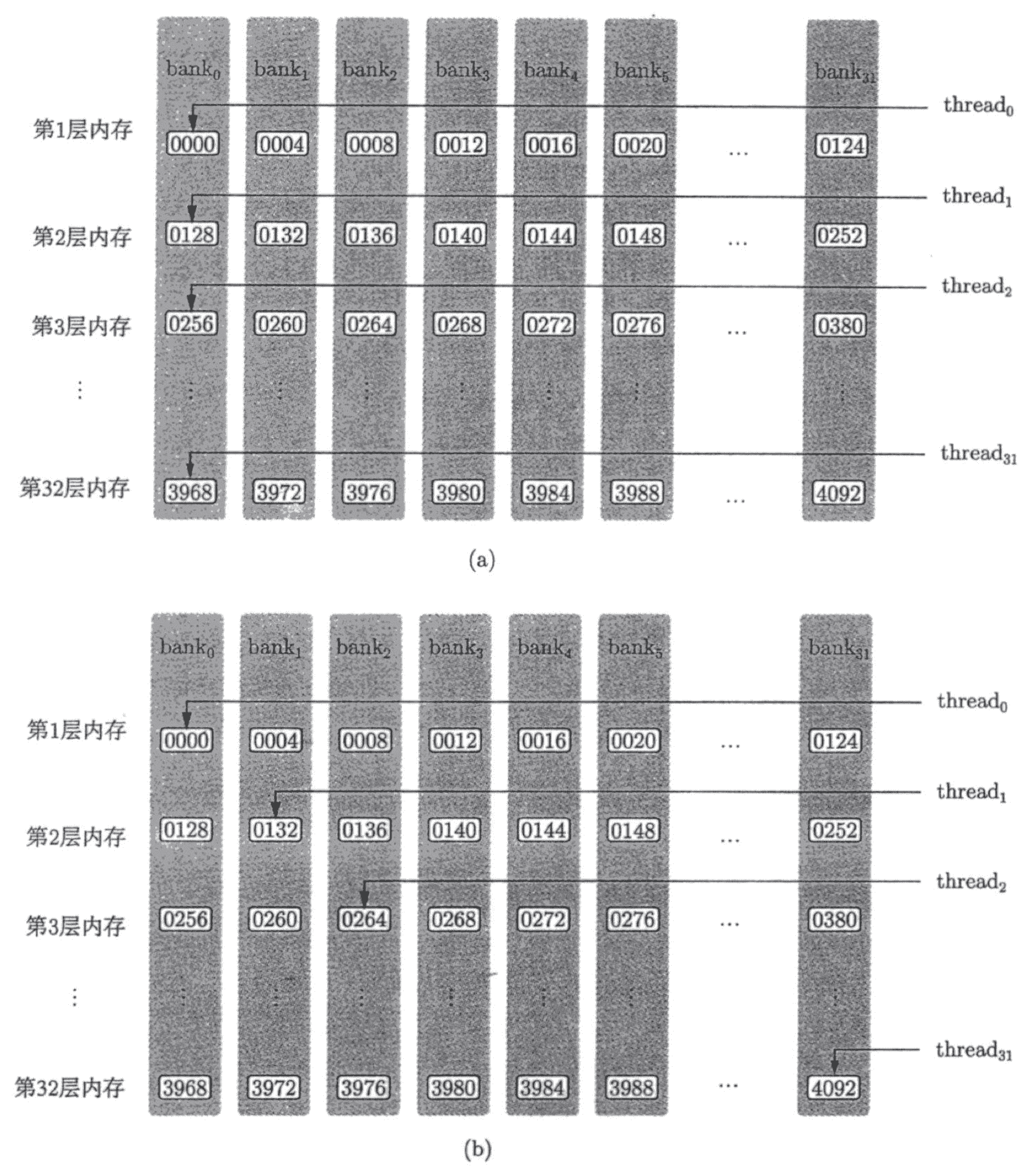
上图 (a) 出现了 bank conflict,图 (b) 正常。为了最大限度地减少 bank 冲突,了解内存地址如何映射到内存 bank 十分重要。
Note
Shared memory 被分割为 32 个 bank,不同的 bank 可以被同时访存,连续的 32-bit 访存被分配到连续的 bank 。Shared memory has 32 banks that are organized such that successive 32-bit words map to successive banks. Each bank has a bandwidth of 32 bits per clock cycle.
下面这个例子中,单精度 float 类型包含 32 bit,因此基本上数组中连续数据将被映射到连续的 bank 上,每个 bank 上一个 float 类型的数据。
__shared__ float sData[32][32];sData[0][0]、 sData[1][0]、sData[2][0]、... 、sData[31][0] 位于 bank 0.
总结
Shared memory 存储在片内,读写速度远高于 global memory,因此可以用来优化全局内存访问合并,但会引入 bank conflict 问题。bank conflict 是指,在访问 Shared memory 时,因多个 threads 访存同一个 bank 中不同地址时,导致并发访问退化为序列化访存,有效带宽下降。